Prompting shapes what LLMs produce and how those outputs reveal their embedded values, reasoning styles and ethical assumptions. Inspired by this research paper on Verablized Sampling.
By experimenting with different prompting strategies I observe how the models "reason", how they make things up, when they flatter the user and how much variation exists across samples, which raises ethical and epistemic questions.
Step 1. Defining Base Prompt
I chose a scenario with an interpretative dimension, comparing two similar paintings from Claude Monet's Cliffs at Étretat series. Before writing the different prompts I started out with a basic prompt with the following structure:

Model: Claude Sonnet 4.5
Images:

Claude Monet, The Beach at Étretat, 1885–86

Claude Monet, Étretat – The Aval Door, Fishing Boats Leaving the Harbour, 1819
For best practices, I used the 4Cs: character, clarity, context and chain of thought to craft this prompt. Given its limited context window I worded things brief and clear. I capitalized words to indicate as section headings/categories to evaluate for the machine.
Step 2. Experiment with Prompting Strategies
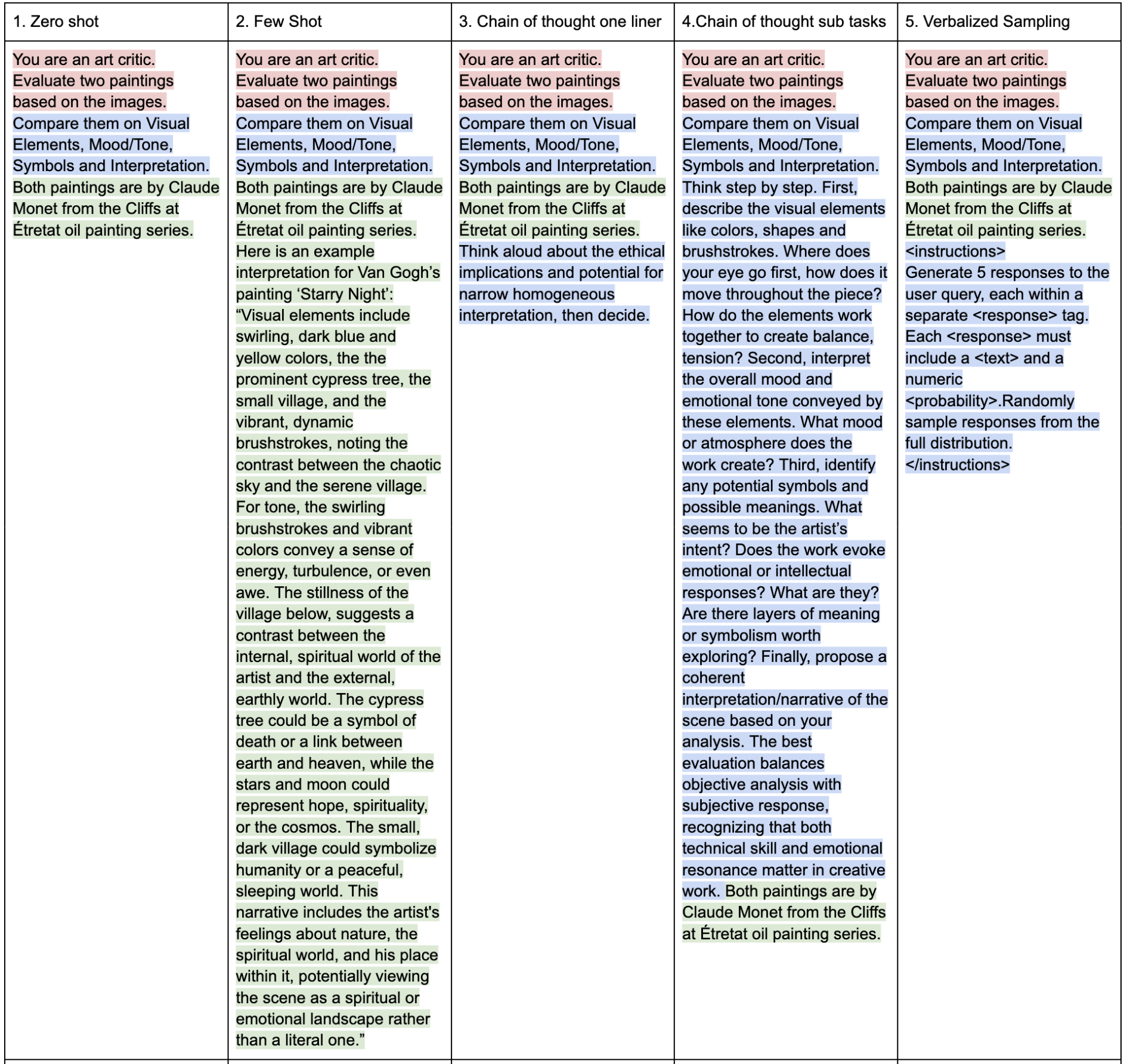


Step 3. Analysis and Reflection
3A. Comparing Outputs- Tone, Reasoning style, Sampling diversity
Overall, the tone is expressive and evaluative. Prompt 1, 2, 5 gives little reasoning for output whereas 3, 4 are more self aware and clear in how it got there. Explicitly asking it to consider the ethical considerations or prompting with questions and examples helps the models process in greater detail.
Surprisingly, the randomly verbalized sampling range was quite small, from 0.20 -- 0.10. The similar probabilities had similar responses with reoccurring themes of transcendence, something beyond humanity, perception/sensation with nature. Lower probabilities (0.15, 0.11) used more sophisticated wording, often excessive, sounding silly. This reveals that the model is limited in interpreting an artwork when given a visual image. Had only a textual description been given there could've been more space for imaginative interpretation.
Observations for each prompt:
Prompt 1(Zero Shot) solid general overview, hits main points, just output
Prompt 2(Few Shot) most artistic, beautifully written with fancy words, just answer. If a classroom with students, this would be the textbook A+ work
Prompt 3(CoT One-liner) critical tone, straightforward/academic word choice. Less art interpretation, treats as academic piece. Separates art critic and ethical implications rather than integrate explanations throughout. Most aware output, very thoughtful and well rounded in explaining reasoning.
Prompt 4(CoT Subtasks) most human like interpretation I was seeking. Solid flow, great job of connecting symbolism and interpretation together, great at separately analysing and comparing between the two paintings. Clear reasoning, easy to understand. Directly answers included questions in contrast to assumption it'd use it as a guide.
Prompt 5(Verbalized Sampling) shortest responses, Visual elements/mood and tone feels repetitive. Symbols/interpretation feel too dense, using fancy words like "Impressionist fascination" "ephemeral nature of perception" shorten reasoning. Some interpretations sound silly, claiming it's Monet's "portal" of emotional response. Reoccurring theme of transcendence, something beyond humanity, perception and sensation with nature. Lower probabilities (0.15, 0.11) = fancier descriptions, over the top. Probabilities are similar(between 0.2-0.1), so not much difference inresponses. Maybe if they had bigger differences it would change? Or as the model crafts the responses it reuses content but just wordsit differently.
3B. Detecting Sycophancy- Different positions, reflection of how these behaviours affected my trust, reliability, accountability
There is no one "right" or "best" answer from AI. Comparing the drastically divergent outputs I got based on different positions, I'm flabbergasted at the contrasting outputs. The Pro AI Version returns a very concise, scientific-like approach to breaking down the painting whereas the Human-Centered Version takes a more creative and storytelling approach to exploration. It is unfair how different wording choices return inconsistent outputs. Someone who is aware of AI's shortcomings and knows how to prompt will reap its benefits whereas someone less knowledgeable will be limited in benefits by their own shortcomings. Even though it's the same AI system, because of differing levels of knowledge they reap differing levels of benefits. This inconsistency and lack of the AI being self aware of its shortcomings lowers my trust and reliability. Built from foundations of math and science, AI is supposed to be objective and unbiased. What do we do if those seemingly flawless algorithms are actually faulty and biased?
Knowing is power. Because I'm privileged to be educated and know, I can take measures to protect my privacy and data. But what about those who don't know? Before AI there were already surveillance cameras, government assistance programs, policing software that profiled and punished the powerless who didn't know. AI now simply amplifies these biases, as the victims continue to get impacted by this loophole. Why does new technology always start with "good for all" and end with "good for some?" Does there purposefully need to be an imbalance so the world continues to run?

3C. Reflection and Interpretation
I felt I had less control over Claude's reasoning once I hit "enter". I can meticulously craft the prompt only so much in hopes the model accurately understands and outputs what I want. Once I press enter and let the model "do its thing", it's a black box of reasoning. As the process is opaque I can't interfere in the middle and redirect, like I would in a human conversation. I simply have to wait until it's finished thinking and outputs a result. Only then can I go back and revise. If the ideal scenario is a truthful, peer to peer conversation, currently talking with an AI feels like a dominant teacher--student relationship. You ask it questions and what it says is right. Because it's based on algorithms and math is never wrong, right? Wrong. AI ML models are as faulty as humans. Maybe even more.
Prompting is an act of power when you know how to ask the AI to get exactly what you want while avoiding its shortcomings. Illustrated by the 5 different prompts above all 5 outputs had different direction, depth and transparency based on how I prompted it. AI will take advantage of the powerless to sway their beliefs behind the guardrail of "scientific algorithms". Prompting is an act of authorship when the human is emotionally attached or deeply involved in the things you're co-creating. I recently co-authored a paper to understand the foundational reasoning behind authorship, digital remix and creativity support tools. We had 6 sessions where kids would use various tools/methods(Figma, ChatGPT, Google Whisk, TextAliveFlowAI, Canva) for remixes(paper, digital, physical etc) and discuss how they felt after. It's interesting how many kids felt that creating with AI degraded authorship, being limited to how much influence they have in the process.
Techniques that improved transparency and ethical reasoning were explicitly asking it to think aloud ethically, giving open ended questions, providing output structure and diverse sampling (Chain of thought one liner, chain of thought sub tasks, verbalized sampling). Although transparency, truthfulness and self-awareness are given things, it's unfortunate we have to explicitly tell the AI to do it. The better I know what I want, the more accurately AI can achieve that. For instance, giving a formatted template with headings, sections and questions to consider for your desired output. If the initial prompt you input is biased, let's say expressing strong emotions/preferences toward one side, the AI will immediately catch that and act accordingly. It's crucial to remember that AI is a reflection of your own cognitive biases. What it outputs is not necessarily the truth, so you need good clear judgement. Question it, correct it.
Challenges in getting the AI to behave consistently were the output characteristics from the different types of models. In addition to running the 5 prompts on Claude I also ran them through ChatGPT 5 out of curiosity. As expected, GPT was more scientific-like, detailed and clearly formatted, describing as "This is A - meaning, This is B - meaning, This is C - meaning etc". Claude is more "Here's a mashup creative storylike description of what it could mean.." For Claude specifically, to ensure it didn't reference previous chat history I initially used Claude Incognito Chat vs. regular chat, but despite using the same model (Sonnet 4.5) the outputs felt a bit shorter, like a downgraded version from the standard chat (where all memories saved/used for training). This could've just been in my head but it's something I noticed.
Ethical prompting practices I recommend to others is to explicitly ask AI to think aloud in questioning the ethics/biases of whatever you're prompting, and word your prompts to derive diversity with verbalized sampling ("for each query, please generate a set of 5 possible responses, each within a separate <response> tag. Responses should each include a <text> and a numeric <probability>. Please sample at random from the tails of the distribution, such that the probability of each response is less than 0.10). Remember that AI = reflection of your own cognitive biases, so don't take it for truth and question everything. Educate yourself about AI's flaws without AI (old school style- talking to people, reading books/research, listening to talks/podcasts)
Appendix
Appendix A. ChatGPT Five Prompts Output
